Concurrency
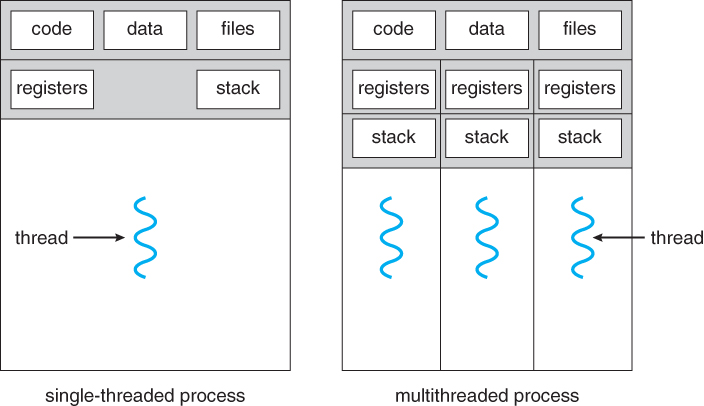
Thread
Processes vs Thread
- Process
- Example: Chrome (process per tab)
- Communicate via pipe() or similar
- Pros: Don’t need new abstractions; good for security
- Cons:
- Cumbersome programming
- High communication overheads
- Expensive context switching
- Thread
- Multiple threads of same process share an address space
- Divide large task across several cooperative threads
- Communicate through shared address space
- Shared: page directories, page tables, code segment
- Not Shared: instruction pointer, stack
- Multiple threads within a single process share:
- Process ID (PID)
- Address space: Code (instructions), Most data (heap)
- Open file descriptors
- Current working directory
- User and group id
- Each thread has its own
- Thread ID (TID)
- Set of registers, including Program counter and Stack pointer
- Stack for local variables and return addresses (in same address space)
Common Programming Models
- Producer/consumer
- Multiple producer threads create data (or work) that is handled by one of the multiple consumer threads
- Pipeline
- Task is divided into series of subtasks, each of which is handled in series by a different thread
- Defer work with background thread
- One thread performs non-critical work in the background (when CPU idle)
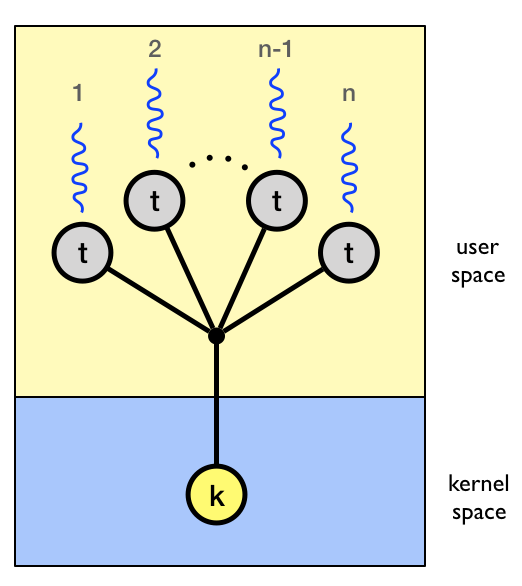
User-level threads: Many-to-one
- Idea
- Implemented by user-level runtime libraries
- Create, schedule, synchronize threads at user-level
- OS is not aware of user-level threads
- OS thinks each process contains only a single thread of control
- Advantages
- Does not require OS support; Portable
- Can tune scheduling policy to meet application demands
- Lower overhead thread operations since no system call
- Disadvantages
- Cannot leverage multiprocessors
- Entire process blocks when one thread blocks
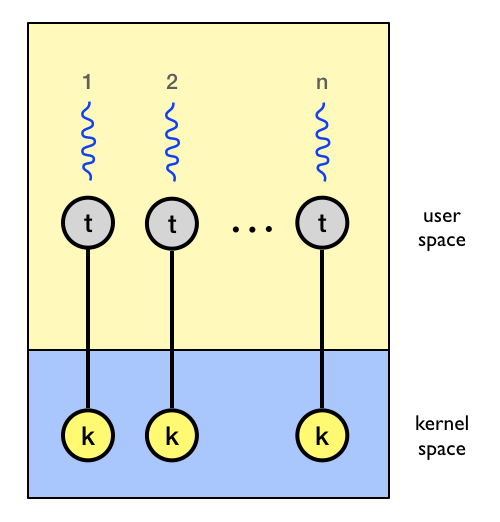
Kernel-level threads: One-to-one
- Idea
- OS provides each user-level thread with a kernel thread
- Each kernel thread scheduled independently
- Thread operations (creation, scheduling, synchronization) performed by OS
- Advantages
- Each kernel-level thread can run in parallel on a multiprocessor
- When one thread blocks, other threads from process can be scheduled
- Disadvantages
- Higher overhead for thread operations
- OS must scale well with increasing number of threads
Thread Schedule Examples
Assume
M[0x123]= 100 initially, and we want to increment it by 1 twiceExample 1 | Thread 1 | Thread 2 | | ——– | ——– | |
mov 0x123, %eax=>%eax= 100
add $0x1, %eax=>%eax= 101
mov %eax, 0x123=>M[0x123]= 101
|mov 0x123, %eax=>%eax= 101
add $0x1, %eax=>%eax= 102
mov %eax, 0x123=>M[0x123]= 102|Example 2 | Thread 1 | Thread 2 | | ——– | ——– | |
mov 0x123, %eax=>%eax= 100
add $0x1, %eax=>%eax= 101
mov %eax, 0x123=>M[0x123]= 101
|mov 0x123, %eax=>%eax= 100
add $0x1, %eax=>%eax= 101
mov %eax, 0x123=>M[0x123]= 101
|
Non-Determinism
- Concurrency leads to non-deterministic results
- Different results even with same inputs
- race conditions
- Whether bug manifests depends on CPU schedule!
- How to program: imagine scheduler is malicious?!
What do we want?
Want 3 instructions to execute as an uninterruptable group
That is, we want them to be atomic
asm= mov 0x123, %eax add $0x1, %eax mov %eax, 0x123More general: Need mutual exclusion for critical sections
- if thread A is in critical section C, thread B isn’t
- (okay if other threads do unrelated work)
Synchronization
- Build higher-level synchronization primitives in OS
- Operations that ensure correct ordering of instructions across threads
- Use help from hardware
Concurrency Objective
- Mutual exclusion (e.g., A and B don’t run at same time)
- solved with locks
- Ordering (e.g., B runs after A does something)
- solved with condition variables and semaphores
Summary
- Concurrency is needed for high performance when using multiple cores
- Threads are multiple execution streams within a single process or address space (share PID and address space, own registers and stack)
- Context switches within a critical section can lead to non-deterministic bugs
Locks
Introduction
Goal: Provide mutual exclusion (mutex)
Atomic operation: No other instructions can be interleaved
- Allocate and Initialize
Pthread_mutex_t mylock = PTHREAD_MUTEX_INITIALIZER;
- Acquire
- Acquire exclusion access to lock;
- Wait if lock is not available (some other process in critical section)
- Spin or block (relinquish CPU) while waiting
Pthread_mutex_lock(&mylock);
- Release
- Release exclusive access to lock; let another process enter critical section
Pthread_mutex_unlock(&mylock);
Implementation Goals
- Correctness
- Mutual exclusion
- Only one thread in critical section at a time
- Progress (deadlock-free)
- If several simultaneous requests, must allow one to proceed
- Deadlock happens when all threads are waiting for lock
- Bounded (starvation-free)
- Must eventually allow each waiting thread to enter
- The waiting time for lock is bounded
- Mutual exclusion
- Fairness: Each thread waits for same amount of time
- Performance: CPU is not used unnecessarily
Spin Lock with Interrupts
Idea
- Turn off interrupts for critical sections
- Prevent dispatcher from running another thread
- Code between interrupts executes atomically
Implementation code ```c= void acquire(lockT *l) { disableInterrupts(); }
void release(lockT *l) { enableInterrupts(); } ```
Disadvantages
- Only works on uniprocessors
- Process can keep control of CPU for arbitrary length
- Cannot perform other necessary work
Spin Lock with Load + Store
Idea: uses a single shared lock variable
Implementation code
// shared variable
boolean lock = false;
void acquire(Boolean *lock) {
while (*lock) /* wait */ ;
*lock = true;
}
void release(Boolean *lock) {
*lock = false;
} Race condition
Thread 1 Thread 2 while (*lock)
lock = true;while (*lock)
*lock = true;- Both threads grab lock!
- Problem: Testing lock and setting lock are not atomic
Spin Lock with xchg
xchg: Atomic exchange or test-and-set
// return what was pointed to by addr // at the same time, store newval into addr int xchg(int *addr, int newval) { int old = *addr; *addr = newval; return old; }Implementation code
typedef struct { int flag; } lock_t; void init(lock_t *lock) { lock->flag = 0; // 0 => unlocked; 1 => locked } void acquire(lock_t *lock) { while (xchg(&lock->flag, 1) == 1) { // spin-wait (do nothing) } // exit loop when flag changed from 0 (unlocked) to 1 (locked) } void release(lock_t *lock) { lock->flag = 0; // set the flag to 0 (unlocked) }
Spin Lock with CAS
CAS: Compare and Swap
// Atomic instruction // set newval to *addr when *addr == expected // return what was pointed to by addr int CompareAndSwap(int *addr, int expected, int newval) { int actual = *addr; if (actual == expected) *addr = newval; return actual; }Implementation code ```c= void acquire(lock_t *lock) {
while(CompareAndSwap(&lock->flag, 0, 1) == 1) { // spin-wait (do nothing)
} }void release(lock_t *lock) { lock->flag = 0; } ```
Exercise with xchg and CAS
Code
c= int a = 1; int b = xchg(&a, 2); int c = CompareAndSwap(&b, 2, 3); int d = CompareAndSwap(&b, 1, 3) ;Result: | a | b | c | d| | ——– | ——– | ——– |-| | 1 | | | | | 2 | 1 | | | | 2 | 1 | 1 | | | 2 | 3 | 1 |1 |
Ticket Locks
Basic spinlocks are unfair
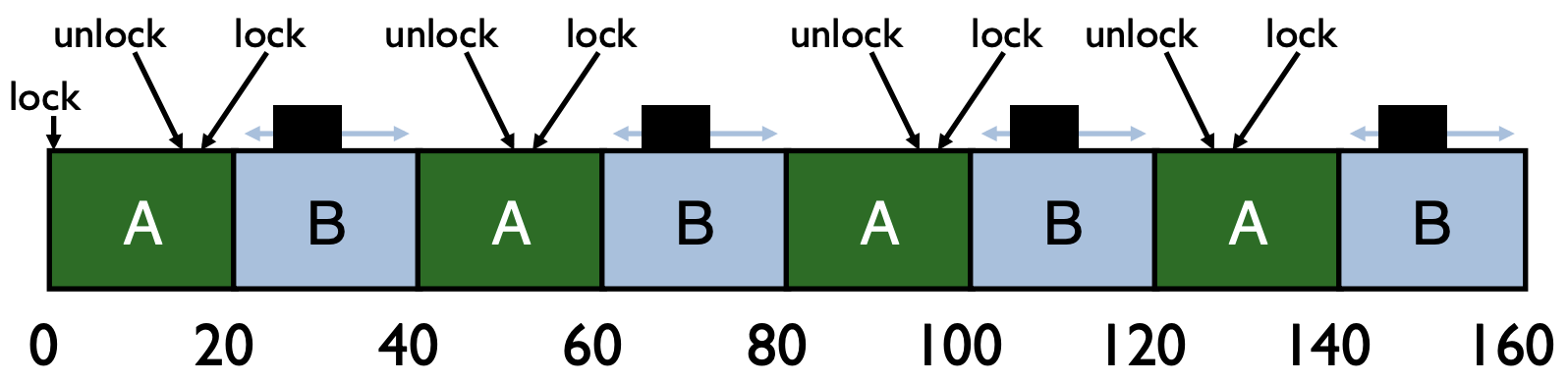
- Scheduler is unaware of locks/unlocks!
Introduction to Ticket Locks
- Idea: reserve each thread’s turn to use a lock.
- Each thread spins until their turn.
- Use new atomic primitive, fetch-and-add
c= int FetchAndAdd(int *ptr) { int old = *ptr; *ptr = old + 1; return old; } - Acquire: Grab ticket; Spin while not thread’s ticket != turn
- Release: Advance to next turn
Example | Time | Event | ticket | Turn |Result | | ——– | ——– | ——– | –| -| | 1 | A
lock()| 0 | 0| A runs| | 2 | Block()| 1 | | B spins until turn = 1| | 3 | Clock()| 2 | | C spins until turn = 2| | 4 | Aunlock()| |1 | B runs| | 5 | Alock()| 3 | | A spins until turn = 3| | 6 | Bunlock()| | 2| C runs| | 7 | Cunlock()| | 3| A runs| | 8 | Aunlock()| | 4| |Ticket Lock Implementation ```c= typedef struct { int ticket; int turn; } lock_t;
void lock_init(lock_t *lock) { lock->ticket = 0; lock->turn = 0; }
void acquire(lock_t *lock) { int myturn = FetchAndAdd(&lock->ticket); while (lock->turn != myturn); // spin }
void release(lock_t *lock) { FetchAndAdd(&lock->turn); } ```
Ticket Lock with Yield
- Spinlock Performance
- Fast when…
- many CPUs
- locks held a short time
- advantage: avoid context switch
- Slow when…
- one CPU
- locks held a long time
- disadvantage: spinning is wasteful
- Fast when…
- CPU Scheduler is Ignorant
- CPU scheduler may run B, C, D instead of A even though B, C, D are waiting for A
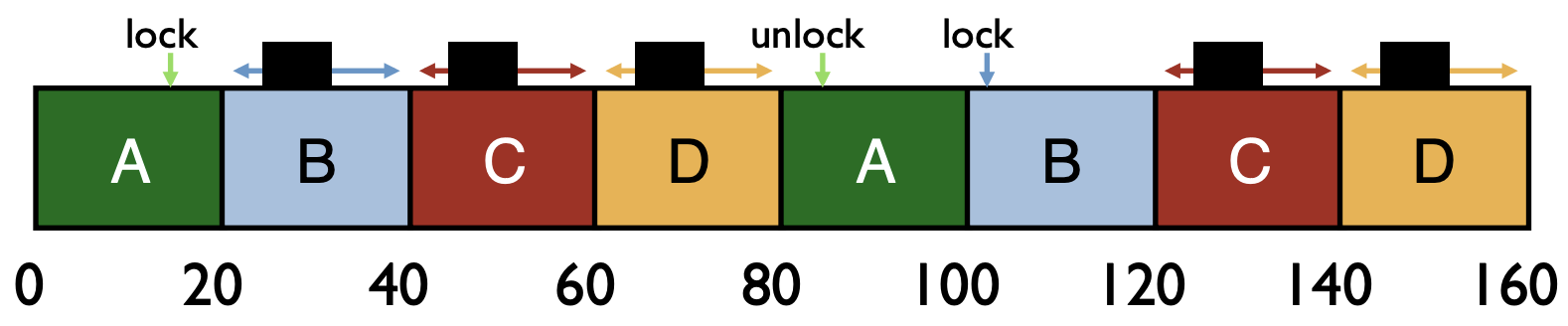
Ticket Locks with Yield ```c= typedef struct { int ticket; int turn; } lock_t;
void lock_init(lock_t *lock) { lock->ticket = 0; lock->turn = 0; }
void acquire(lock_t *lock) { int myturn = FetchAndAdd(&lock->ticket); while (lock->turn != myturn) { yield(); // yield instead of spin } }
void release(lock_t *lock) { FetchAndAdd(&lock->turn); } ```
Yield instead of Spin
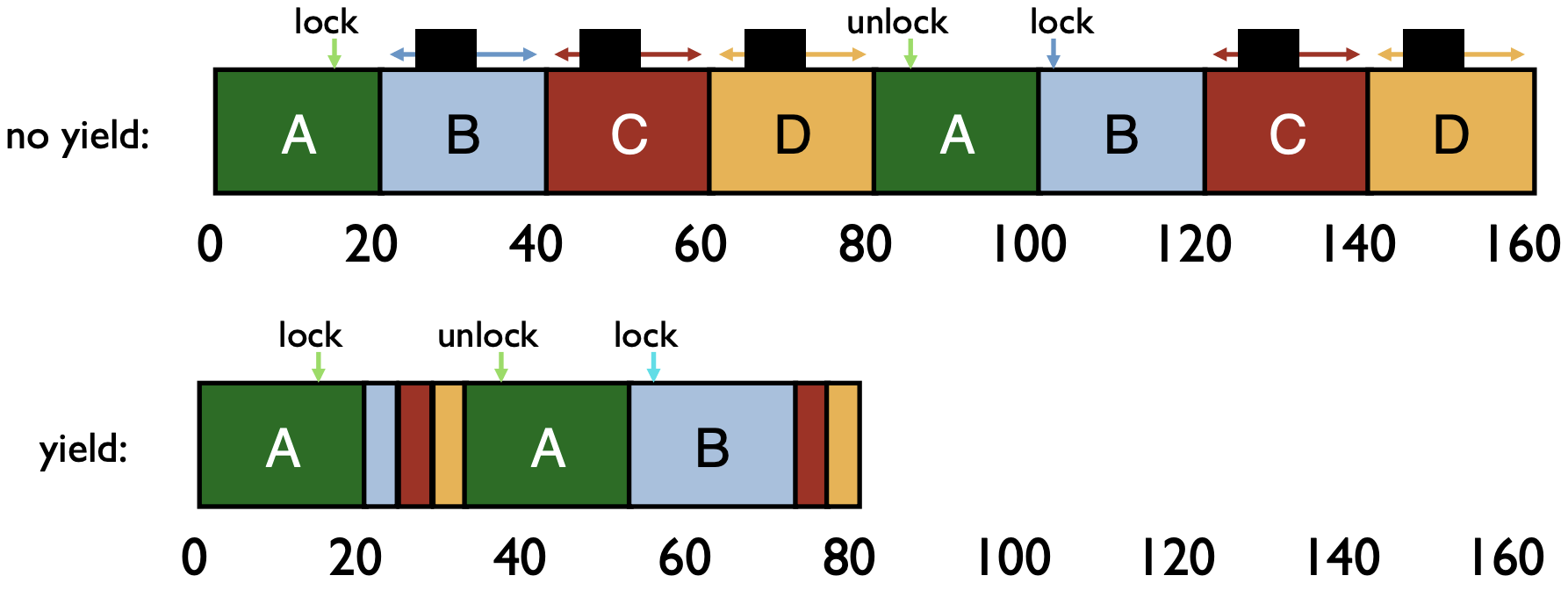
- Time Comparison: Yield vs Spin
- Assumption
- Round robin scheduling, 10ms time slice
- Process A, B, C, D, E, F, G, H, I, J in the system
- Timeline
- A: lock() … compute … unlock()
- B: lock() … compute … unlock()
- …
- J: lock() … compute … unlock()
- A: lock() … compute … unlock()
- …
- If A’s compute is 20ms long, starting at t = 0, when does B get lock with spin ?
110 ms
A…J A B 100 10
- If B’s compute is 30ms long, when does C get lock with spin ?
320 ms
A…J A…J A…J A B C 100 100 100 10 10
- If context switch time = 1ms, when does B get lock with yield ?
- 29 ms
A B…J A B 10 9 10
- Assumption
Queue Lock
Motivation
- Time complexity of spinlock
- Without yield: O(threads * time_slice)
- With yield: O(threads * context_switch)
- Even with yield, spinning is slow with high thread contention
- Time complexity of spinlock
Idea
- Block and put thread on waiting queue instead of spinning
- Remove waiting threads from scheduler ready queue
- (e.g.,
park()andunpark(threadID)) - Scheduler runs any thread that is ready
Example
- Assumption
- A & C has 60ms of work
- A, B, D contend for lock
- C not contending
- Context switch + yield takes 5ms
- Timeline |Time| Event|Running | Runnable | Waiting | | ——– | ——– | ——– | -| -| |Initial| | | A, B, C, D | | |0-20|A scheduled|A | B, C, D| | |20-25|B scheduled & blocked| | C, D, A|B | |25-45|C scheduled |C| D, A|B | |45-50|D scheduled & blocked|| A, C|B, D | |50-70|A scheduled|A| C|B, D | |70-90|C scheduled|C| A|B, D | |90-110|A scheduled & finished|A| C|B, D | |110-130|C scheduled & finished|C| B| D | |130-150|B scheduled & finished|B| D| | |150-170|D scheduled & finished|D| | |
- Assumption
Incorrect Implementation ```c= typedef struct { bool lock = false; bool guard = false; queue_t q; } LockT;
// 1. Grab guard // 2. If lock is held, add to queue and park // 3. If lock is not held, grab the lock void acquire(LockT *l) { while (XCHG(&l->guard, true)); if (l->lock) { qadd(l->q, tid); l->guard = false; park(); // blocked
} else { l->lock = true; l->guard = false; } }// 1. Grab guard // 2. If queue is empty, release hte lock // 3. If the queue is not empty, unpark head of queue void release(LockT *l) { while (XCHG(&l->guard, true)); if (qempty(l->q)) l->lock=false; else unpark(qremove(l->q));
l->guard = false; }```
Questions and Answers
Why is guard used? To ensure queue operations is thread safe
Why OK to spin on guard? Very shhort critical section
In release(), why not set
lock = falsewhen unpark?lock == trueis passed from one thread to the next
Race Condition for Previous Implementation | Thread 1 (in lock) | Thread 2 (in unlock)| | ——– | ——– | | if (l->lock) {
qadd(l->q, tid);
l->guard = false;
park() |
while (TAS(&l->guard, true));
if (qempty(l->q)) // false!!
else unpark(qremove(l->q));
l->guard = false;
|Correct Implementation ```c= typedef struct { bool lock = false; bool guard = false; queue_t q; } LockT;
void acquire(LockT *l) { while (XCHG(&l->guard, true)); if (l->lock) { qadd(l->q, tid); setpark(pid); // notify of plan l->guard = false; park(); // blocked
} else { l->lock = true; l->guard = false; } }void release(LockT *l) { while (XCHG(&l->guard, true)); if (qempty(l->q)) l->lock=false; else unpark(qremove(l->q));
l->guard = false; }```
Time Comparison: Yield vs Blocking
- Assumption
- Round robin scheduling, 10ms time slice
- Process A, B, C, D, E, F, G, H, I, J in the system
- Context switch takes 1ms
- Timeline
- A: lock() … compute … unlock()
- B: lock() … compute … unlock()
- …
- J: lock() … compute … unlock()
- A: lock() … compute … unlock()
- …
- If A’s compute is 30ms long, starting at t = 0, when does B get lock with yield?
48 ms
A B…J A B…J A B 10 9 10 9 10
- If A’s compute is 30ms long, starting at t = 0, when does B get lock with blocking?
39 ms
A B…J A A B 10 9 10 10
- Assumption
Queue Lock vs Spin Lock
- Each approach is better under different circumstances
- Uniprocessor
- Waiting process is scheduled à Process holding lock isn’t
- Waiting process should always relinquish processor
- Associate queue of waiters with each lock (as in previous implementation)
- Multiprocessor
- Waiting process is scheduled -> Process holding lock might be
- Spin or block depends on how long, t, before lock is released
- Lock released quickly -> Spin-wait
- Lock released slowly -> Block
- Quick and slow are relative to context-switch cost, C
Condition Variables
Ordering
Idea: Thread A runs after Thread B does something
Example: Join
c= pthread_t p1, p2; Pthread_create(&p1, NULL, mythread, "A"); Pthread_create(&p2, NULL, mythread, "B"); // join waits for the threads to finish Pthread_join(p1, NULL); Pthread_join(p2, NULL); return 0;### Condition VariablesCondition Variable: queue of waiting threads
B waits for a signal on CV before running:
wait(CV, …)A sends signal to CV when time for B to run:
signal(CV, …)wait(cond_t *cv, mutex_t *lock)- assumes the lock is held when wait() is called
- puts caller to sleep + releases the lock (atomically)
- when awoken, reacquires lock before returning
signal(cond_t *cv)- wake a single waiting thread (if >= 1 thread is waiting)
- if there is no waiting thread, just return, doing nothing
Join Attempt 1: No State
Code ```c= // parent void thread_join() { Mutex_lock(&m); // x Cond_wait(&c, &m); // y Mutex_unlock(&m); // z }
// child void thread_exit() { Mutex_lock(&m); // a Cond_signal(&c); // b Mutex_unlock(&m); // c } ```
Intended schedule
Time 1 2 3 4 5 6 Parent x y z Child a b c Broken schedule
Time 1 2 3 4 5 Parent x y Child a b c - Parent is stuck because nobody will call signal
Rule of Thumb 1
- Keep state in addition to CV’s
- CV’s are used to signal threads when state changes
- If state is already as needed, thread doesn’t wait for a signal!
Join Attempt 2: No Mutex Lock
Code ```c= // parent void thread_join() { Mutex_lock(&m); // w // If the child process already finished executing // the parent process doesn’t need to wait if (done == 0) // x Cond_wait(&c, &m); // y Mutex_unlock(&m); // z }
// child void thread_exit() { done = 1; // a Cond_signal(&c); // b } ```
Intended schedule
Time 1 2 3 4 5 6 Parent w x y z Child a b Broken schedule
Time 1 2 3 4 5 Parent w x y Child a b - Parent is stuck again
Join Attempt 3: State + Mutex Lock
Code ```c= // parent void thread_join() { Mutex_lock(&m); // w if (done == 0) // x Cond_wait(&c, &m); // y Mutex_unlock(&m); // z }
// child void thread_exit() { Mutex_lock(&m); // a done = 1; // b Cond_signal(&c); // c Mutex_unlock(&m); // d } ```
Schedule
Time 1 2 3 4 5 6 7 Parent w x y z Child a b c d Rule of Thumb 2
- Hold mutex lock while calling wait/signal
- Ensures no race between interacting with state and wait/signal
Producer/Consumer Problem
- Example: UNIX pipes
A pipe may have many writers and readers
Internally, there is a finite-sized buffer
Writers add data to the buffer
- Writers have to wait if buffer is full
Readers remove data from the buffer
- Readers have to wait if buffer is empty
Implementation:
- reads/writes to buffer require locking
- when buffers are full, writers must wait
- when buffers are empty, readers must wait
Start (consumer) | +---------v---------------------------+------+ Buf: | | data | | +---------+---------------------------^------+ | End (producer)
- Producer/Consumer Problem
Producers generate data (like pipe writers)
Consumers grab data and process it (like pipe readers)
Producer/consumer problems are frequent in systems (e.g. web servers)
General strategy use condition variables to:
- make producers wait when buffers are full
- make consumers wait when there is nothing to consume
P/C Attempt 1: One CV
Code ```c= // 1. Producer grabs the lock // 2. Check whether the buffer is full. If so, wait. // 3. Put something to the buffer // 4. Signal consumers to read // 5. Release the lock void producer(void arg) { for (int i = 0; i < loops; i++) { Mutex_lock(&m); // p1 if (numfull == max) // p2 Cond_wait(&cond, &m); // p3 do_fill(i); // p4 Cond_signal(&cond); // p5 Mutex_unlock(&m); // p6 } }
// 1. Consumer grabs the lock // 2. Check whether the buffer is empty. If so, wait. // 3. Get the content from buffer and remove it. // 4. Signal consumers to write // 5. Release the lock void consumer(void arg) { while (1) { Mutex_lock(&m); // c1 if (numfull == 0) // c2 Cond_wait(&cond, &m); // c3 int tmp = do_get(); // c4 Cond_signal(&cond); // c5 Mutex_unlock(&m); // c6 } } ```
Broken schedule
Time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 P p1 p2 p4 p5 p6 p1 p2 p3 C1 c1 c2 c3 C2 c1 c2 c3 c4 c5 - At time 16, Consumer 1 could signal Consumer 2 to wake up
P/C Attempt 2: Two CVs
How to wake the right thread? Use two condition variables
Code ```c= void producer(void arg) { for (int i = 0; i < loops; i++) { Mutex_lock(&m); // p1 if (numfull == max) // p2 Cond_wait(&empty, &m); // p3 do_fill(i); // p4 Cond_signal(&fill); // p5 Mutex_unlock(&m); // p6 } }
void consumer(void arg) { while (1) { Mutex_lock(&m); // c1 if (numfull == 0) // c2 Cond_wait(&fill, &m); // c3 int tmp = do_get(); // c4 Cond_signal(&empty); // c5 Mutex_unlock(&m); // c6 } } ```
Broken schedule
Time 1 2 3 4 5 6 7 8 9 10 11 12 P p1 p4 p5 p6 C1 c1 c2 c3 c4 C2 c1 c4 c5 c6 - At time 12, Consumer 1 wakes up but has nothing to read
- Note: When
signal()is called, the thread may not resume immediately
P/C Attempt 3: Two CVs with While
Idea: Recheck the shared variable is still in the state you want after waking up
Code ```c= void producer(void arg) { for (int i = 0; i < loops; i++) { Mutex_lock(&m); // p1 while (numfull == max) // p2 Cond_wait(&empty, &m); // p3 do_fill(i); // p4 Cond_signal(&fill); // p5 Mutex_unlock(&m); // p6 } }
void consumer(void arg) { while (1) { Mutex_lock(&m); // c1 while (numfull == 0) // c2 Cond_wait(&fill, &m); // c3 int tmp = do_get(); // c4 Cond_signal(&empty); // c5 Mutex_unlock(&m); // c6 } } ```
Rule of Thumb 3
- Whenever a lock is acquired, recheck assumptions about state!
- Another thread could grab lock in between signal and wakeup from wait
- Note that some libraries also have “spurious wakeups”
- (may wake multiple waiting threads at signal or at any time)
Summary
- Rules of Thumb for CVs
- Keep state in addition to CV’s
- Always do wait/signal with lock held
- Whenever thread wakes from waiting, recheck state
wait(cond_t *cv, mutex_t *lock)- assumes the lock is held when wait() is called
- puts caller to sleep + releases the lock (atomically)
- when awoken, reacquires lock before returning
signal(cond_t *cv)- wake a single waiting thread (if >= 1 thread is waiting)
- if there is no waiting thread, just return, doing nothing
Semaphores
Introduction
- Condition variables have no state (other than waiting queue)
- Programmer must track additional state
- Semaphores have state: track integer value
- State cannot be directly accessed by user program
- But state determines behavior of semaphore operations
Semaphore Operations
- Allocate and Initialize
c= sem_init(sem_t *s, int initval) { s->value = initval; }- User cannot read or write value directly after initialization
- Wait or Test (sometime P() for Dutch)
sem_wait(sem_t*)- Decrements sem value, Waits until value of sem is >= 0
- Signal or Post (sometime V() for Dutch)
sem_post(sem_t*)- Increment sem value, then wake a single waiter
Build Lock from Semaphore
typedef struct {
sem_t sem;
} lock_t;
void init(lock_t *lock) {
sem_init(&lock->sem, 1);
}
void acquire(lock_t *lock) {
sem_wait(&lock->sem);
}
void release(lock_t *lock) {
sem_post(&lock->sem);
} Join with CV vs Semaphores
Join with Condition Variable ```c= // parent void thread_join() { Mutex_lock(&m); // w if (done == 0) // x Cond_wait(&c, &m); // y Mutex_unlock(&m); // z }
// child void thread_exit() { Mutex_lock(&m); // a done = 1; // b Cond_signal(&c); // c Mutex_unlock(&m); // d } ```
Join with Semaphores ```c= sem_t s; sem_init(&s, 0);
void thread_join() { sem_wait(&s); }
void thread_exit() { sem_post(&s); }
```
Join with Semaphores Example 1
s s s +---+ parent wait() +---+ child post() +---+ | 0 |+----------------->| -1|+---------------->| 0 | +---+ +---+ +---+ ^ ^ | | Parent blocked Parent resumesJoin with Semaphores Example 2
s s s +---+ child post() +---+ parent wait() +---+ | 0 |+----------------->| 1 |+---------------->| 0 | +---+ +---+ +---+
P/C: 1 Producer & 1 Consumer with Buffer of Size 1
Use 2 semaphores
- emptyBuffer: Initialize to 1
- fullBuffer: Initialize to 0
Producer
c= while (1) { sem_wait(&emptyBuffer); Fill(&buffer); sem_signal(&fullBuffer); }Consumer
c= while (1) { sem_wait(&fullBuffer); Use(&buffer); sem_signal(&emptyBuffer); }Example 1: Producer comes first | Time | Current Thread | emptyBuffer | fullBuffer | | ——– | ——– | ——– | -| | Initial | | 1 | 0 | | 1 | Producer | 0 | 1 | | 2 | Consumer | 1 | 0 | | 3 | Producer | 0 | 1 |
Example 2: Consumer comes first | Time | Current Thread | emptyBuffer | fullBuffer | | ——– | ——– | ——– | -| | Initial | | 1 | 0 | | 1 | Consumer | 1 | -1 | | 2 | Producer | 0 | 0 | | 3 | Consumer | 1 | 0 |
P/C: 1 Producer & 1 Consumer with Buffer of Size N
Use 2 semaphores
- emptyBuffer: Initialize to N
- fullBuffer: Initialize to 0
Producer
c= int i = 0; while (1) { sem_wait(&emptyBuffer); Fill(&buffer[i]); i = (i + 1) % N; sem_signal(&fullBuffer); }Consumer
c= int j = 0; while (1) { sem_wait(&fullBuffer); Use(&buffer[j]); j = (j + 1) % N; sem_signal(&emptyBuffer); }Example 1: Producer comes first (N = 3) | Time | Curr | empty
Buffer | full
Buffer | Note| | ——– | ——– | ——– | -| -| | Initial | | 3 | 0 | | 1 | P1 | 2 | 1 |wait(emptyBuffer) + fill + signal(fullBuffer)| | 2 | P2 | 1 | 2 |wait(emptyBuffer) + fill + signal(fullBuffer)| | 3 | P3 | 0 | 3 |wait(emptyBuffer) + fill + signal(fullBuffer)| | 4 | P4 | -1 | 3 |wait(emptyBuffer)| | 5 | C1 | 0 | 2 |wait(fullBuffer) + use + signal(emptyBuffer)| | 6 | C2 | 1 | 1 |wait(fullBuffer) + use + signal(emptyBuffer)| | 7 | P4 | 0 | 2 |fill + signal(fullBuffer)|Example 2: Two consumers come first (N = 3) | Time | Curr | empty
Buffer | full
Buffer | Note| | ——– | ——– | ——– | -| -| | Initial | | 3 | 0 | | 1 | C1 | 3 | -1 | wait(fullBuffer)| | 2 | C2 | 3 | -2 |wait(fullBuffe)| | 3 | P | 2 | -1 |wait(emptyBuffer) + fill + signal(fullBuffer)| | 4 | C1 | 3 | -1 | use + signal(emptyBuffer)|
P/C: Multiple Producers & Consumers
- Requirements
- Each consumer must grab unique filled element
- Each producer must grab unique empty element
- Attempt 1
Producer
c= while (1) { sem_wait(&emptyBuffer); my_i = findempty(&buffer); Fill(&buffer[my_i]); sem_signal(&fullBuffer); }Consumer
c= while (1) { sem_wait(&fullBuffer); my_j = findfull(&buffer); Use(&buffer[my_j]); sem_signal(&emptyBuffer); }Problem:
findfullandfindemptyare not thread-safe
- Attempt 2
Producer
c= while (1) { sem_wait(&mutex); sem_wait(&emptyBuffer); my_i = findempty(&buffer); Fill(&buffer[my_i]); sem_signal(&fullBuffer); sem_signal(&mutex); }Consumer
c= while (1) { sem_wait(&mutex); sem_wait(&fullBuffer); my_j = findfull(&buffer); Use(&buffer[my_j]); sem_signal(&emptyBuffer); sem_signal(&mutex); }Problem
- Deadlock: Consumer grabs
mutexand wait forfullBufferfor ever
- Deadlock: Consumer grabs
- Attempt 3
Producer
c= while (1) { sem_wait(&emptyBuffer); sem_wait(&mutex); my_i = findempty(&buffer); Fill(&buffer[my_i]); sem_signal(&mutex); sem_signal(&fullBuffer); }Consumer
c= while (1) { sem_wait(&fullBuffer); sem_wait(&mutex); my_j = findfull(&buffer); Use(&buffer[my_j]); sem_signal(&mutex); sem_signal(&emptyBuffer); }Problem
- Cannot operate on multiple buffer locations at the same time
- Only 1 thread at at time can be using of filling different buffers
- Attempt 4
Producer
c= while (1) { sem_wait(&emptyBuffer); sem_wait(&mutex); my_i = findempty(&buffer); sem_signal(&mutex); Fill(&buffer[my_i]); sem_signal(&fullBuffer); }Consumer
c= while (1) { sem_wait(&fullBuffer); sem_wait(&mutex); my_j = findfull(&buffer); sem_signal(&mutex); Use(&buffer[my_j]); sem_signal(&emptyBuffer); }Advantage
- Works and increases concurrency; only finding a buffer is protected by mutex;
- Filling or Using different buffers can proceed concurrently
Reader/Writer Locks
Idea
- Let multiple reader threads grab lock (shared)
- Only one writer thread can grab lock (exclusive)
- No reader threads
- No other writer threads
Code ```c= typedef struct_rwlock_t { sem_t lock; // reader lock sem_t writelock; int readers; // number of readers } rwlock_t;
void rwlock_init(rwlock_t*rw) { rw->readers = 0; // initialize locks to 1, similar to mutex initialization sem_init(&rw->lock, 1);
sem_init(&rw->writelock, 1); }void rwlock_acquire_readlock(rwlock_t *rw) { sem_wait(&rw->lock); rw->readers++; if (rw->readers == 1) sem_wait(&rw->writelock); sem_post(&rw->lock); }
void rwlock_release_readlock(rwlock_t *rw) { sem_wait(&rw->lock); rw->readers–; if (rw->readers == 0) sem_post(&rw->writelock); // let other writes sem_post(&rw->lock); }
void rwlock_acquire_writelock(rwlock_t *rw) { sem_wait(&rw->writelock); }
void rwlock_release_writelock(rwlock_t *rw) { sem_post(&rw->writelock); } ```
Example | Time | Current Action | lock | writelock | readers | | ——– | ——– | ——– | -| -| | Initial | | 1 | 1 | 0 | | 1 | T1
acquire_readlock|01 | 0 | 1| | 2 | T2acquire_readlock|01 | 0 | 2| | 3 | T3acquire_writelock| 1 | -1 | 2| | 4 | T1release_readlock|01 | -1 | 1| | 5 | T2release_readlock|01 | 0 | 0|Quiz 1
- T1:
acquire_readlock()=> T1 running - T2:
acquire_readlock()=> T2 running - T3:
acquire_writelock()=> T3 blocked, waiting for write lock
- T1:
Quiz 2
- T6:
acquire_writelock()=> T6 running - T4:
acquire_readlock()=> T4 blocked, waiting for read lock - T5:
acquire_readlock()=> T5 blocked, waiting for read lock
- T6:
Build Zemaphore from Lock and CV
typedef struct {
int value;
cond_t cond;
lock_t lock;
} zem_t;
void zem_init(zem_t *z, int value) {
z->value = value;
cond_init(&z->cond);
lock_init(&z->lock);
}
// waits until value > 0. and decrement
void zem_wait(zem_t *z) {
lock_acquire(&z->lock);
z->value--;
while (z->value < 0)
cond_wait(&z->cond);
lock_release(&z->lock);
}
// increment value, then wake a single waiter
void zem_post(zem_t *z) {
lock_acquire(&z->lock);
z->value++;
cond_signal(&z->cond);
lock_release(&z->lock);
} Summary
- Semaphores are equivalent to locks + condition variables
- Can be used for both mutual exclusion and ordering
- Semaphores contain state
- How they are initialized depends on how they will be used
- Init to 0: Join (1 thread must arrive first, then other)
- Init to N: Number of available resources
- sem_wait(): Decrement and waits until value >= 0
- sem_post(): Increment value, then wake a single waiter (atomic)
- Can use semaphores in producer/consumer and for reader/writer locks
Concurrency Bugs
Concurrency in Medicine: Therac-25 (1980’s)
“The accidents occurred when the high-power electron beam was activated instead of the intended low power beam, and without the beam spreader plate rotated into place. Previous models had hardware interlocks in place to prevent this, but Therac-25 had removed them, depending instead on software interlocks for safety. The software interlock could fail due to a race condition.”
“…in three cases, the injured patients later died.”
- Source: http://en.wikipedia.org/wiki/Therac-25
Concurrency Study
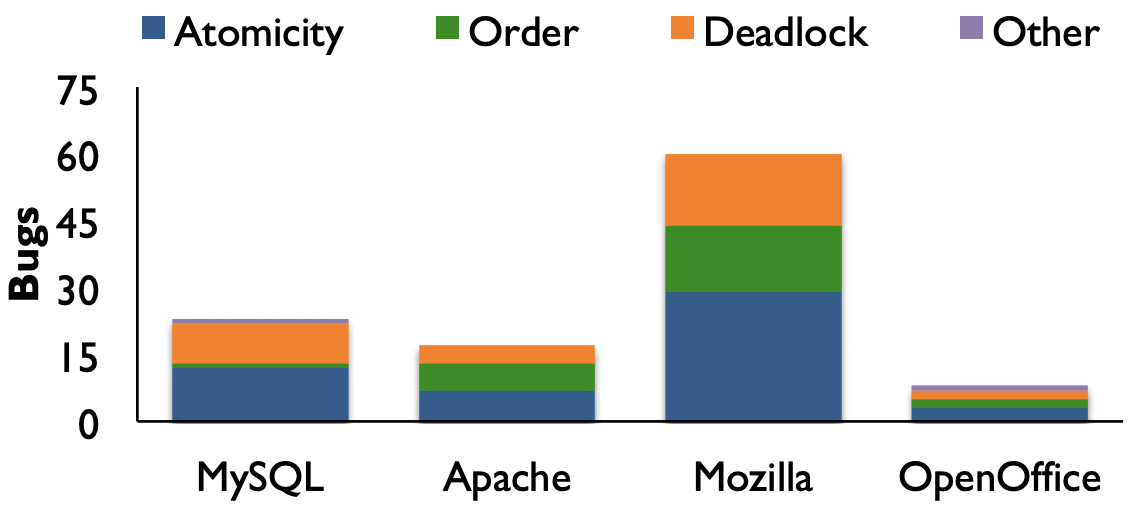
Atomicity: MySQL
Bug
c= // Thread 1 if (thd->proc_info) { // ... fputs(thd->proc_info, /*...*/); // ... }c= // Thread 2 thd->proc_info = NULL;Fix
c= // Thread 1 pthread_mutex_lock(&lock); if (thd->proc_info) { // ... fputs(thd->proc_info, /*...*/); // ... } pthread_mutex_unlock(&lock);c= // Thread 2 pthread_mutex_lock(&lock); thd->proc_info = NULL; pthread_mutex_unlock(&lock);
Ordering: Mozilla
Bug
c= // Thread 1 void init() { // ... mThread = PR_CreateThread(mMain, /*...*/); // ... }// Thread 2 void mMain(/*...*/) { // ... mState = mThread->State; // ... }Fix
// Thread 1 void init() { // ... mThread = PR_CreateThread(mMain, /*...*/); pthread_mutex_lock(&mtLock); mtInit = 1; pthread_cond_signal(&mtCond); pthread_mutex_unlock(&mtLock); // ... }// Thread 2 void mMain(/*...*/) { // ... pthread_mutex_lock(&mtLock); while (mtInit == 0) pthread_cond_wait(&mtCond, &mtLock); pthread_mutex_unlock(&mtLock); mState = mThread->State; // ... }Deadlock
Definition
No progress can be made because two or more threads are waiting for the other to take some action and thus neither ever does
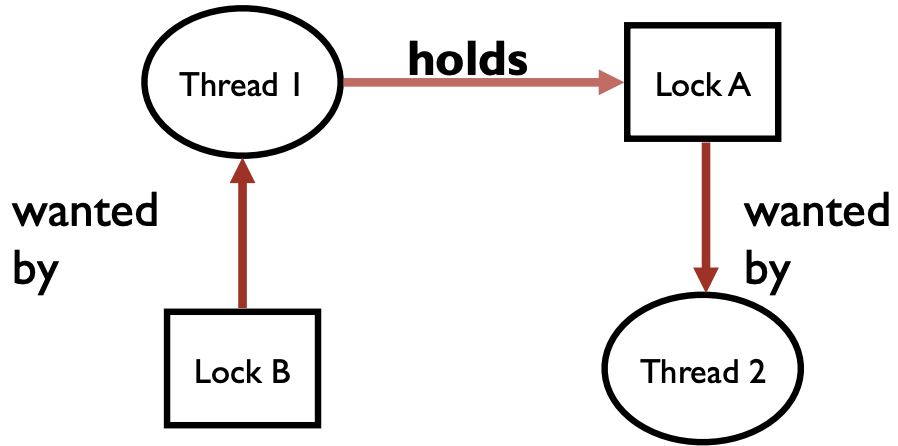
Example 1: Circular Dependency
Code | Thread 1 | Thread 2 | | ——– | ——– | |
lock(&A);
lock(&B);(blocked) |lock(&B);
lock(&A);(blocked)
|Circular Dependency
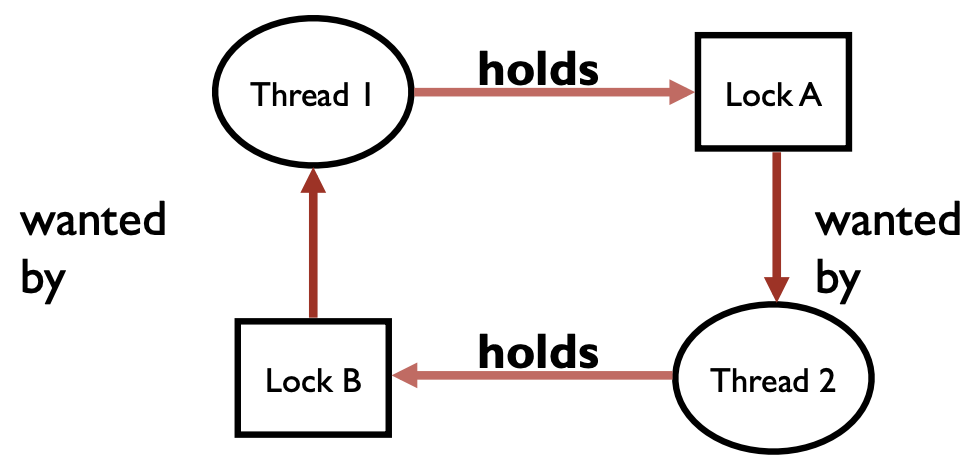
- Cycle in dependency graph -> possible to have deadlock
Fix Deadlock Code | Thread 1 | Thread 2 | | ——– | ——– | |
lock(&A);lock(&B);|lock(&A);
lock(&A);|Non-Circular Dependency
Example 2: Encapsulation
- Code
set_t *set_intersection(set_t *s1, set_t *s2) {
set_t *rv = malloc(sizeof(*rv));
mutex_lock(&s1->lock);
mutex_lock(&s2->lock);
for (int i = 0; i < s1->len; i++) {
if (set_contains(s2, s1->items[i])) {
set_add(rv, s1->items[i]);
}
}
mutex_unlock(&s2->lock);
mutex_unlock(&s1->lock);
}- Deadlock scenario
- Thread 1:
rv = set_intersection(setA, setB); - Thread 2:
rv = set_intersection(setB, setA);
- Thread 1:
- Encapsulation
c= if (m1 > m2) { // grab locks in high-to-low address order pthread_mutex_lock(m1); pthread_mutex_lock(m2); } else { pthread_mutex_lock(m2); pthread_mutex_lock(m1); }- Problem: Deadlock happens when
m1 == m2
- Problem: Deadlock happens when
Deadlock Theory
- Deadlocks can only happen with these four conditions:
- mutual exclusion
- hold-and-wait
- no preemption
- circular wait
- Can eliminate deadlock by eliminating any one condition
1. Mutual Exclusion
Problem: Threads claim exclusive control of resources that they require
Strategy: Eliminate locks! Replace locks with atomic primitive
Lock-free
add- Implement
addusing lockc= void add(int *val, int amt) { Mutex_lock(&m); *val += amt; Mutex_unlock(&m); } - Atomic primitive
CompareAndSwapc= int CompareAndSwap(int *address, int expected, int new) { if (*address == expected) { *address = new; return 1; // success } return 0; // failure } - Implement
addwithout lockc= void add(int *val, int amt) { do { int old = *value; } while (!CompareAndSwap(val, old, old + amt); }
- Implement
Wait-free Linked List Insert
Implement
insertusing lockc= void insert(int val) { node_t *n = malloc(sizeof(*n)); n->val = val; lock(&m); n->next = head; head = n; unlock(&m); }Implement
insertusing while loopc= void insert(int val) { node_t *n = Malloc(sizeof(*n)); n->val = val; do { n->next = head; } while (!CompareAndSwap(&head, n->next, n)); }### 2. Hold and Wait
Problem: Threads hold resources allocated to them while waiting for additional resources
Strategy: Acquire all locks atomically once. Can release locks over time, but cannot acquire again until all have been released
How to do this? Use a meta lock:
c= lock(&meta); lock(&L1); /*...*/ lock(&L10); unlock(&L10); /*...*/ unlock(&L1); unlock(&meta);Disadvantages
- Locks are not fine-grained
3. No Preemption
Problem: Resources (e.g., locks) cannot be forcibly removed from threads that are
Strategy: if thread can’t get what it wants, release what it holds
top: lock(A); if (trylock(B) == -1) { // try to lock B unlock(A); // if failed, also unlock A goto top; }Disadvantages
- Live lock: A situation in which two or more processes continuously change their states in response to changes in the other process(es) without doing any useful work
Circular Wait
Circular chain of threads such that each thread holds a resource (e.g., lock) being requested by next thread in the chain.
Strategy:
- decide which locks should be acquired before others
- if A before B, never acquire A if B is already held!
- document this, and write code accordingly
Works well if system has distinct layers
Concurrent Data Structures
Scalability
N times as much work on N cores as done on 1 core.
Strong scaling
Fix input size, increase number of cores
e.g. Matrix multiplication: \(A_{m\times n}\times B_{n\times d}\) requires \(O(mnd)\) FLOPS (floating point operations per second)
Time ^ | | ** | ** | ** | ** | ** ** | ** ** | ** ** ** | ** ** ** ** +-----++-----++-----++-----++----> Number of Cores 0 1 2 3 4
Weak scaling
Increase input size with number of cores
e.g. Matrix multiplication
A B FLOPS 1 core 100 × 100 100 × 100 106 2 core 100 × 200 200 × 100 2×106 3 core 100 × 300 300 × 100 2×106 4 core 100 × 400 400 × 100 4×106 Time ^ | | ** ** ** ** | ** ** ** ** | ** ** ** ** | ** ** ** ** | ** ** ** ** | ** ** ** ** | ** ** ** ** | ** ** ** ** +-----++-----++-----++-----++----> Number of Cores 0 1 2 3 4
Counter
Non-thread-safe Counter ```c= typedef struct __counter_t { int value; } counter_t;
void init(counter_t * c) { c->value = 0; } void increment(counter_t * c) { c->value++; } int get(counter_t * c) { return c->value; } ```
- Problem: Two threads calls
incrementat the same time
- Problem: Two threads calls
Thread-safe counter
typedef struct __counter_t { int value; pthread_mutex_t lock; } counter_t; void init(counter_t * c) { c->value = 0; } void increment(counter_t * c) { Pthread_mutex_lock(&c->lock); c->value++; Pthread_mutex_unlock(&c->lock); } int get(counter_t * c) { Pthread_mutex_lock(&c->lock); return c->value; Pthread_mutex_unlock(&c->lock); }Linearizability
Even if two threads execute in parallel on multiple cores, the effect that you see should be as if all of them are executed in some linear order.
Example: T1 and T2 call
incrementfirst, then T3 callsget.Since T3 arrived after T1 and T2, we would want T3 to see the values after T1 and T2 have finished executing as if these were three instructions executed by a single processor
The Underlying Problem
- Ticket lock
struct spinlock_t { int current_ticket; // turn int next_ticket; } void spin_lock(spinlock_t *lock) { t = atomic_inc(lock->next_ticket) while (t != lock->current_ticket); // spin } void spin_unlock(spinlock_t *lock) { lock->current_ticket++; }- If one of the thread holds the lock, all of the other threads need to check the lock
- So each lock acquisition becomes more and more expensive as you go from like two to four to eight…
Approximate Counter (Sloppy Counter)
- Idea
- Maintain a counter per-core and a global counter
- Global counter lock
- Per-core locks if more than 1 thread per-core
- Increment:
- update local counters at threshold update global
- Read:
- global counter (maybe inaccurate?)
- Code
typedef struct __counter_t {
int global; // global count
pthread_mutex_t glock; // global lock
int local[NUMCPUS]; // local count (per cpu)
pthread_mutex_t llock[NUMCPUS]; // ... and locks
int threshold; // update frequency
} counter_t;
// init: record threshold, init locks, init values of all local counts and
// global count
void init(counter_t* c, int threshold) {
c->threshold = threshold;
c->global = 0;
pthread_mutex_init(&c->glock, NULL);
for (int i = 0; i < NUMCPUS; i++) {
c->local[i] = 0;
pthread_mutex_init(&c->llock[i], NULL);
}
}
// usually, just grab local lock and update local amount once local
// count has risen by ’threshold’, grab global lock and transfer local values to it
void update(counter_t* c, int threadID, int amt) {
pthread_mutex_lock(&c->llock[threadID]);
c->local[threadID] += amt; // assumes amt > 0
if (c->local[threadID] >= c->threshold) { // transfer to global
pthread_mutex_lock(&c->glock);
c->global += c->local[threadID];
pthread_mutex_unlock(&c->glock);
c->local[threadID] = 0;
}
pthread_mutex_unlock(&c->llock[threadID]);
}
// get: just return global amount (which may not be perfect)
int get(counter_t* c) {
pthread_mutex_lock(&c->glock);
int val = c->global;
pthread_mutex_unlock(&c->glock);
return val; // only approximate!
}Concurrent Linked List
First Attempt
c= void List_Insert(list_t *L, int key) { pthread_mutex_lock(&L->lock); node_t *new = malloc(sizeof(node_t)); if (new == NULL) { perror("malloc"); pthread_mutex_unlock(&L->lock); return; // fail } new->key = key; new->next = L->head; L->head = new; pthread_mutex_unlock(&L->lock); return; // success }Better Implementation (Shorter Critical Section)
c= void List_Insert(list_t *L, int key) { pthread_mutex_lock(&L->lock); node_t *new = malloc(sizeof(node_t)); if (new == NULL) { perror("malloc"); return; // fail } pthread_mutex_unlock(&L->lock); new->key = key; new->next = L->head; L->head = new; pthread_mutex_unlock(&L->lock); return; // success }
Hash Table from List
Idea
- Avoid contention by using different locks
Code ```c= #define BUCKETS (101) typedef struct __hash_t { list_t lists[BUCKETS]; } hash_t;
int Hash_Insert(hash_t *H, int key) { int bucket = key % BUCKETS; return List_Insert(&H->lists[bucket], key); } ```
Concurrent Queue
void Queue_Enqueue(queue_t *q, int value) {
node_t *tmp = malloc(sizeof(node_t));
assert(tmp != NULL);
tmp->value = value;
tmp->next = NULL;
pthread_mutex_lock(&q->tailLock);
q->tail->next = tmp;
q->tail = tmp;
pthread_mutex_unlock(&q->tailLock);
}
int Queue_Dequeue(queue_t *q, int *value) {
pthread_mutex_lock(&q->headLock);
node_t *tmp = q->head;
node_t *newHead = tmp->next;
if (newHead == NULL) {
pthread_mutex_unlock(&q->headLock);
return -1; // queue was empty
}
*value = newHead->value;
q->head = newHead;
pthread_mutex_unlock(&q->headLock);
free(tmp);
return 0;
}Summary
Simple approach: Add a lock to each method?!
Check for scalability – weak scaling, strong scaling
Avoid cross-thread, cross-core traffic
- Per-core counter
- Buckets in hashtable